Overview
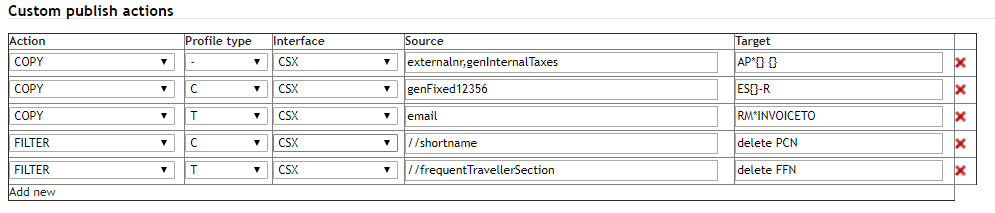
Description
| Field | Description |
|---|---|
| Action | Select COPY or FILTER for your action |
| Profile type | A distinction is made between Traveller, Company, and Traveller as well as Company. T is for Traveller, C for Company and "-" is for both profile types(T & C). Select between T,C and - to determine on which profile type the values should either be published or filtered out |
| Interface | Indicate which interface the action will affect |
| Source | Indicate the source needed for a customized copy action or the filter needed to remove specific copy actions already programmed in the standard User Interface (UI) |
| Target | Indicate the target for copy actions or for filter actions, insert a free text describing the value that has been filtered out |
The sources for the COPY function of company profile data can be found under Copy - Company. The sources for the COPY function of traveller profile data is found in the first line (header line) of the traveller CSV that is downloaded from Faces. For fields that allow the use of the "Add new" function, multiple information i.e multiple frequent flyer programs are present in the CSV file. If 0-n lists (FQTV or passports) are copied, either an index (passports0, passports1) can be used, or use the index placeholder '#' (# passports). The latter then copies all existing indexes. Any extra copy sources not covered by the CSV are listed under Copy - Traveller.
FILTER examples can be found under Filter - Traveller and Filter - Company
Filters use XPath expressions to find element nodes that should be excluded from the published XML.
How to write an XPath expression?
All XPath expressions examples from this guide refer to the following XML:
<library> <books> <book type=”classic”> <author> <firstname>Charles</firstname> <lastname>Dickens</lastname> </author> <title>A Tale of Two Cities</title> <price currency="EUR">15.99</price> </book> <book type=”fantasy”> <author> <firstname>George</firstname> <lastname>Martin</lastname> <birthdate>20.02.1998</birthdate> </author> <title>A Game of Thrones</title> <price currency="GBP">21.99</price> </book> <book type=”science”> <author> <firstname>Stephen</firstname> <lastname>Hawking</lastname> </author> <title>Brief Answers to the Big Questions</title> <price>13.99</price> </book> </books> <manager> <firstname>John</firstname> <lastname>Doe</lastname> </manager> <owner> <firstname>Jeff</firstname> <lastname>Bezos</lastname> </owner> </library>
To better understand this guide, you can use http://xpather.com/ to try XPath expressions on previously shown XML. You can also use this website in the future to validate your Filters, but please do not use any XMLs containing sensitive data.
General syntax.
The simplest and the most efficient way to provide an XPath to an element is to list all elements from the root element to the desired one, separated by a slash(/).
library/manager/lastname - selects the library owner's first name.
In case an exact path is unknown or does not include all desired nodes, a double slash(//) or an asterisk(*) can be used.
double slash(//) selects nodes in the document from the current node that match the selection no matter where they are
//firstname - selects library/books/book/author/firstname, library/manager/firstname and library/owner/firstname
asterisk(*) is a wildcard, which can be used instead of providing the name of the node. It basically means there must be an element, but its name does not matter.
library/*/firstname - selects library/manager/firstname and library/owner/firstname
library/*/*/*/firstname - selects library/books/book/author/firstname
Predicates
Predicates are used to find a specific node or a node that contains a specific value.
Predicates are always embedded in square brackets.
A predicate can be:
- a boolean(true or false) expression.
- a positive integer (representing the element's order position starting with 1)
- a node (which is expected to exist)
//book[price>17.00] - selects all books with price higher than 17.00
//book[2] - selects the second book
//book[price/@currency] - selects all books which price has a currency attribute*
*At(@) represents an attribute node. You can think of it like you would think of a child node. If we rewrite <price> element following way:
<price> <currency>GBP</ currency > <amount>21.99</amount> </price>
then the corresponding expression would be //book[price/currency]. It is possible to write an XPath expression selecting an attribute (//book/@type), but currently Faces does not support attribute filtering, so the only usage of attributes for us are predicates.
There are many useful functions that can be used in predicates:
//book[last()] – selects the last book
//book[position()<=2] – selects first two books
//price[text()<20] – selects prices below 20 (text() function returns the actual value stored inside of an element)
//author[contains(firstname,'rles')] – selects authors whose first name contains ‘rles’
//*[starts-with(firstname,'J')] – selects all nodes, which have a child node with a value starting with ‘J’
Note that the predicate always refers to the whole node it is written after, so there is a difference between //book/price[@currency] and //book[price/@currency]. The first one selects only prices with a currency attribute, stored inside of a book and the second one selects whole books with prices with a currency attribute.
The following operators can be used in predicates:
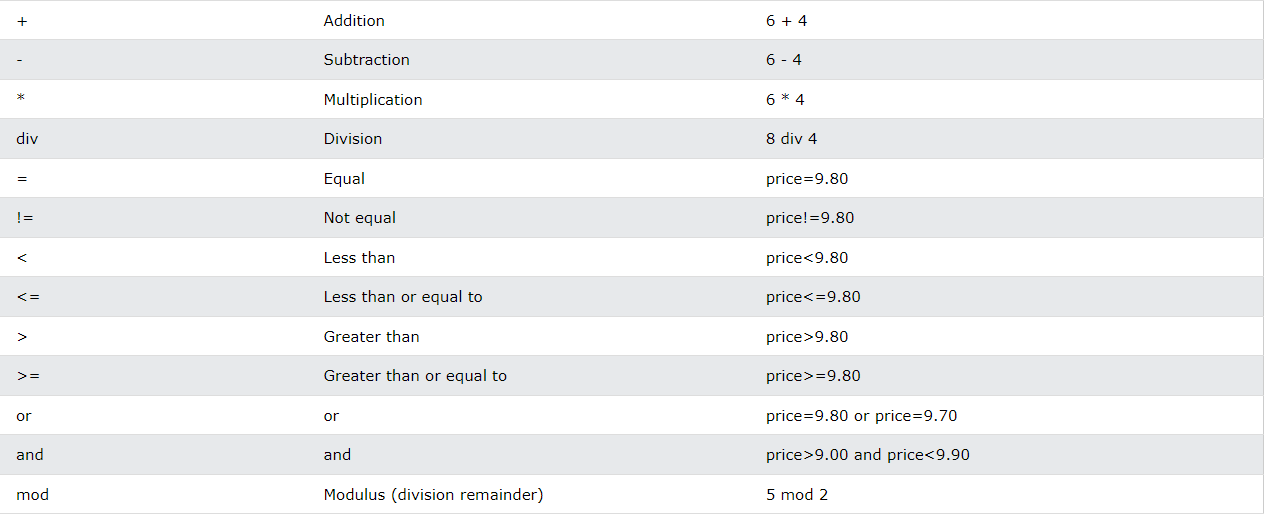
Tips
The more details you provide, the better.
In our case, library/books/book[1] and //book[1] are equivalent, but the first one is faster because it does not have to look for book elements inside of manager and owner nodes.
A more detailed filter also helps to avoid mistakes. If you want to exclude firstname from all author elements and use //firstname as a Filter, manager and owner nodes will also lose their firstname, which may be unwanted.Use starts-with() over contains() when you expect the substring to be at the beginning.
//books/book[starts-with(title, "A Game")] will give up on "A Tale of Two Cities" as soon as it reaches the character "T". //books/book[contains(title, "A Game")] will search the entire string through which is bad for performance. It also can lead to unwanted elements being filtered.- Avoid using the | operator. Better create two separate filters to improve readability and simplify debugging.